Architecture overview
The ALTextToSpeech module is composed of an API whose role is to interface commands sent to NAOqi and the TTS synthesis module. The synthesis module embeds sound processing routines allowing to apply pitch shifting or to add a second voice. In this last case, the voices are mixed together and sent to the audio engine.
| Note: |
This module is only available on the robot. |
|---|
Architecture diagram:
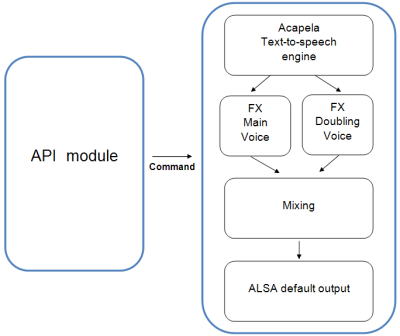
- The Text-To-Speech engine transforms text into speech signals. The
speech generation is based on voice packages called "voices" in the
rest of this document.
Note: In the RoboCup package, there is only one voice included, namely the "Heather22Enhanced" voice.
- The FX module performs a pitch-shifting on the main voice. It can be done twice in order to create a double voice effect. For each module the parameters can be defined separately.
- The mixing block simply sums the two voices, with a variable gain on the
second voice, and a variable delay between the main voice and the second one.
The delay provides a way to compensate for the latency between the first voice
and the second one, due to the FX processing, and can also be used as a simple
sound effect.
Note: The variable gain on the second voice does not change the overall voice volume, only the relative volume between each voice.
- The resulting signal is sent to the ALSA sound engine, available on the robot's system.
Example of use: if you want to make the robot say a sentence, you have to call the method 'say' of the audio module. Each sentence is enqueued in the synthesis module. The synthesis module outputs audio frames, that are processed in the sound processing objects if necessary. The frames coming from each voice are then mixed together and sent to the default ALSA output (two output channels).